
NVIDIA CEO Jensen Huang stated bluntly during the earnings call that Agentic AI has reached an inflection point, with computing power directly translating into revenue. Huang believes that without computing power, tokens cannot be generated, and without tokens, revenue growth cannot be achieved; the massive capital expenditures by cloud service providers will ultimately convert directly into income. Additionally, the company confirmed it is close to finalizing a significant infrastructure partnership with OpenAI, with order demand already extending to 2027.
$NVIDIA(NVDA.US)$ With a record-breaking earnings report, NVIDIA attempted to counter external skepticism about an AI bubble. However, its stock price reversed to a decline after the earnings call, despite having risen more than 4% during after-hours trading.
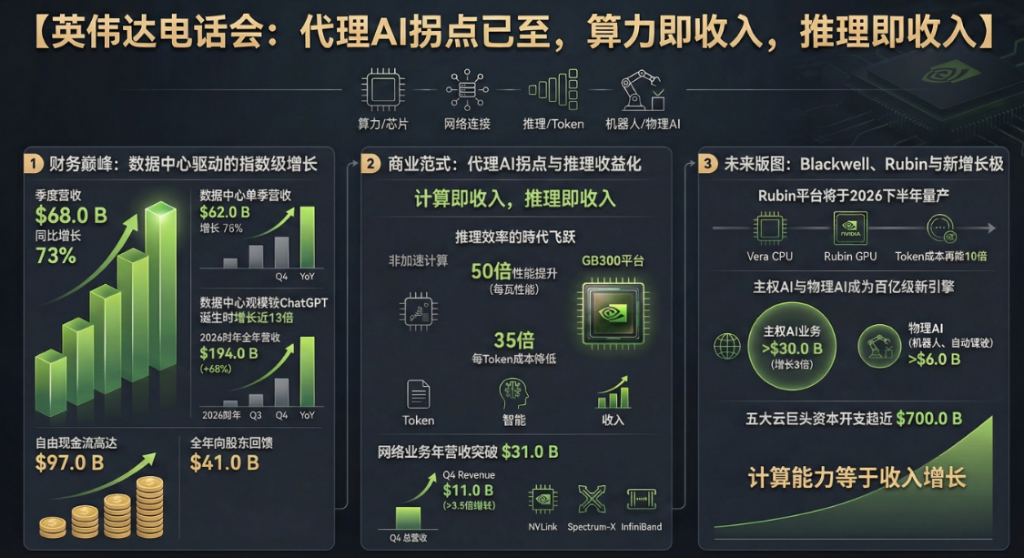
On February 25, after the U.S. stock market closed, NVIDIA announced its latest quarterly revenue of $68 billion and provided strong guidance. During the earnings call, NVIDIA CEO Jensen Huang stated directly that Agentic AI has reached an inflection point, with computing power translating directly into revenue.
 Jensen Huang emphasized that without computing power, tokens cannot be generated, and without tokens, revenue growth cannot be achieved. The substantial capital expenditures of cloud service providers will ultimately translate directly into income.
Jensen Huang emphasized that without computing power, tokens cannot be generated, and without tokens, revenue growth cannot be achieved. The substantial capital expenditures of cloud service providers will ultimately translate directly into income.
Huang also highlighted the soaring adoption of agents by enterprises, stating that Grace Blackwell paired with NVLink is the leader in inference performance. Moreover, he noted that the current space data center economy remains 'barren,' but the situation will evolve over time.
From the overall financial data and supply chain outlook, NVIDIA’s growth engine remains robust. CFO Colette Kress revealed at the start of the earnings call:
Total revenue reached $68 billion, representing a year-over-year increase of 73%, with further acceleration in growth compared to the third quarter on a sequential basis.
She explicitly pointed out that most of the revenue growth was still driven by the data center business. NVIDIA's stock price rose over 4% in after-hours trading but gradually narrowed its gains after the earnings call.
Key Highlights from the Earnings Call:
Product Roadmap and Technological Breakthroughs: Nearly 9 gigawatts of Blackwell infrastructure have been deployed, with performance surpassing competitors by 50 times; the first Vera Rubin samples have been shipped to customers, with mass production expected in the second half of 2026; token inference costs will be reduced tenfold. Through software optimization (e.g., CUDA), the performance of GB200 NVL72 was increased fivefold within four months.
Strategic Partnerships and Investments: A partnership agreement with OpenAI is nearing completion; Meta has deployed millions of Blackwell and Rubin GPUs; a $10 billion investment in Anthropic. Acquisition of Grok low-latency inference technology; deepened industrial AI collaboration with Siemens, Dassault Systèmes, and Synopsys.
The AI inflection point has arrived: Jensen Huang emphasized that 'agentic AI' has reached a turning point, where computing power will directly translate into revenue. A paradigm shift is occurring in data centers, with each center constrained by power limitations, making performance per watt the critical metric.
The rise of physical AI: It contributed over $6 billion in revenue in the fiscal year 2026; robotaxis and autonomous driving are expected to scale from thousands to millions of units.
Growth in sovereign AI: The sovereign AI business surpassed $30 billion in fiscal year 2026, tripling year-over-year, driven primarily by Canada, France, the Netherlands, Singapore, and the UK.
Gross margin outlook: Expected to remain in the mid-70% range for the full year, supported by ongoing architectural innovations delivering multi-fold improvements in performance per watt.
Future outlook: Revenue for Q1 of fiscal year 2027 is projected at $78 billion, with data centers driving most of the growth. Global data center capital expenditure is expected to reach $3-4 trillion by 2030. Strategic inventory and production capacity have been secured to meet demand through 2027, though tight supply of high-end architectures is acknowledged.
Jensen Huang: Computing power equals revenue, with AI agents driving a new wave of demand
Addressing concerns about whether sustained high capital expenditures by tech giants could lead to financial exhaustion or loss of momentum, Jensen Huang clearly stated during the Q&A session that he is not worried about AI companies running out of funds.
Jensen Huang emphasized:
I am highly confident about their cash flow growth, and the reason is very simple. We are now witnessing the inflection point of agentic AI and the practicality of intelligent agents. The industry has reached another turning point.
He distilled the core logic of the current phase into one sentence:
It is crucial to recognize that 'reasoning now equates directly to our clients' revenue.'
Jensen Huang elaborated in detail on the operational landscape of this business model:
Due to the vast number of tokens being generated by intelligent agents, with highly effective outcomes, when these agents write code, they produce thousands, tens of thousands, or even hundreds of thousands of tokens, as they may run for minutes to hours. Consequently, these systems, or agent systems, are spawning different intelligent agents in a collaborative manner.
Jensen Huang added:
The volume of tokens being generated is truly, truly growing exponentially. Therefore, we need to perform reasoning at an accelerated pace. When reasoning occurs at higher speeds, every token becomes monetized (dollarized), translating directly into revenue.
Looking ahead, Jensen Huang explicitly stated:
Fundamentally, because every company relies on software, and every software will depend on AI, every company will generate tokens.
He believes that this new form of computation 'will not regress.' Jensen Huang remarked:
If we believe that generating tokens represents the future of computing... then we will start building this capability from now and continue expanding from here.
This perspective aligns seamlessly with Jensen Huang’s statements during the previous quarter's earnings call, where he segmented the industry into three structural platform shifts: from traditional CPUs to GPU computing, from conventional machine learning to generative AI, and from generative AI to AI agents, emphasizing that each shift independently supports substantial investment.
Partnering with OpenAI and ecosystem investments to consolidate global computing power dominance
When responding to analysts' questions about strategic investments, Jensen Huang confirmed that NVIDIA is close to finalizing a partnership with OpenAI.
This collaboration was initially outlined last year as a potential $100 billion AI infrastructure project, with recent reports suggesting NVIDIA may also make an investment of approximately $30 billion.
Huang described OpenAI as a 'once-in-a-generation' company, emphasizing that NVIDIA's investment goal is to ensure everything from large language models to robotics is built on NVIDIA's platform. He stated:
We want to seize this tremendous opportunity as we stand at the beginning of a new era of computing.
Additionally, when discussing various AI companies and projects, Huang specifically mentioned the recently highly regarded open-source AI agent OpenClaw.
He noted that the enthusiasm of enterprise-grade independent software vendors (ISVs) in developing agent systems on tool platforms further confirms that the market is at an inflection point of explosive growth. Huang remarked:
The adoption rate of AI between Claude Cowork and OpenClaw’s computational demands is surging.
In response to discussions by Elon Musk and others regarding space-based data centers, Huang commented that while current economic viability is low, it will improve:
In space... heat dissipation can only occur through conduction, requiring significantly larger radiators. Thus, the methods we use on Earth differ somewhat from those in space. However, many distinct computational problems genuinely need to be addressed in space, so NVIDIA is already the world’s first GPU in space. Hopper is already in space.
He pointed out that one of the best use cases for GPUs in space is imaging.
Extremely tight supply chain
Regarding the supply chain, Kress revealed:
We believe that our current inventory and supply commitments are sufficient to meet future demand, with shipping schedules extending into the 2027 calendar year. Due to the overwhelming demand for NVIDIA's infrastructure, even Hopper and the six-year-old Ampere architecture products have been sold out in the cloud.
In terms of product iteration cycles, new and old transitions are occurring seamlessly. The Blackwell architecture is ramping up strongly, while the next-generation Vera Rubin platform has already taken a substantive step forward. Kress stated:
Earlier this week, we shipped the first Vera Rubin samples to customers and remain on track to begin volume shipments in the second half of this year. We expect every cloud model builder to deploy Vera Rubin.
In addition to advanced components (such as high-bandwidth memory HBM) causing ongoing supply constraints for the latest chip architectures, capacity limitations have also spilled over into NVIDIA’s traditional gaming business. Kress stated:
Although we would very much like to have more additional supply, we do believe that the supply situation (for the gaming business) will remain extremely tight in the coming quarters.
Full transcript translation of NVIDIA's fourth-quarter earnings call for fiscal year 2026 (AI tool-assisted):
Company participants: Colette Kress, Executive Vice President and Chief Financial Officer; Jensen Huang, Founder, President, and Chief Executive Officer; Toshiya Hari, Vice President of Investor Relations and Strategic Finance
Other participants (analysts): Aaron Rakers, Wells Fargo & Co; Antoine Chkaiban, New Street Research; Atif Malik, Citi; Ben Reitzes, Melius Research; CJ Muse, Cantor Fitzgerald & Co.; Harlan Sur, JPMorgan; Jim Schneider, Goldman Sachs; Joseph Moore, Morgan Stanley; Mark Lipacis, Evercore ISI; Stacy Rasgon, Bernstein Research; Tim Arcuri, UBS Group; Vivek Arya, Bank of America Merrill Lynch.
Conference Presentation
Operator: Good afternoon. My name is Sarah, and I will be your operator for today's conference call. I would like to welcome everyone to NVIDIA’s Fourth Quarter Earnings Conference Call. All lines have been muted to prevent any background noise.
There will be a question-and-answer session following the speakers' remarks. (Operator Instructions) Thank you. Toshiya Hari, you may now begin the conference.
Toshiya Hari: Thank you. Good afternoon, and welcome to NVIDIA’s Fiscal Year 2026 Conference Call. Joining me today on behalf of NVIDIA are President and Chief Executive Officer Jensen Huang and Executive Vice President and Chief Financial Officer Colette Kress. This call is being webcast live on NVIDIA’s Investor Relations website. A replay of this webcast will be available after the discussion of our fiscal year 2027 financial results.
The content of today’s conference is the property of NVIDIA. No part of it may be reproduced or transcribed without our prior written consent. During this call, we may make forward-looking statements based on current expectations. These statements are subject to significant risks and uncertainties, and our actual results may differ materially.
For a discussion of factors that could affect our future financial performance and business, please refer to the disclosures in today’s earnings release, our latest Form 10-K and Form 10-Q, as well as any Form 8-K reports that we may file with the Securities and Exchange Commission. All of our statements are made as of today, February 25, 2026, based on information currently available to us. Except as required by law, we assume no obligation to update any such statements. During this call, we will discuss non-GAAP financial measures.
You can find reconciliations of these non-GAAP financial measures to GAAP financial measures in the CFO commentary published on our website. With that, I will now turn the call over to Colette.
Colette Kress: Thank you, Toshiya. We delivered another outstanding quarter, setting new records in revenue, operating profit, and free cash flow.
Total revenue reached $68 billion, representing a year-over-year increase of 73% and further acceleration from the third quarter. Quarterly growth also hit a record, with our data center revenue increasing by $11 billion. Our customer base continues to diversify and expand, including cloud service providers, hyperscale computing companies, AI model developers, enterprises, and sovereign nations. Demand for our Blackwell architecture, which is designed with extreme co-design at data center scale, continues to strengthen, with inference deployment growing alongside training. The transition to accelerated computing and the proliferation of AI in existing hyperscale workloads continue to drive our growth.
Agent-based (Agentic) and physical AI applications, built on increasingly intelligent and multimodal models, are beginning to drive our financial performance. For the full year, data centers generated $194 billion in revenue, a year-over-year increase of 68%. Since the release of ChatGPT in fiscal year 2023, our data center business has expanded nearly 13-fold. Looking ahead, we expect quarterly revenue for each quarter of calendar year 2026 to grow sequentially, surpassing the $500 billion Blackwell and Rubin revenue opportunity we shared last year.
We believe we are well-positioned with inventory and supply commitments to meet future demand, including shipments extending into calendar year 2027. Every data center is constrained by power. Given these limitations and the need to maximize AI factory revenue, customers will make critical architectural decisions based on performance per watt. SemiAnalysis recently crowned NVIDIA as the 'King of Inference,' as the latest results from InferenceX solidified our leadership in the inference domain: compared to off-grid solutions, GB300 and NVL72 achieve up to 50 times the performance per watt and reduce per-token costs by 35 times.
Ongoing optimizations to the CUDA software have enabled us to boost the performance of GB200 NVL72 by up to five times in just four months. NVIDIA delivers exceptionally low per-token costs, while data centers running on NVIDIA can generate extremely high revenue. Our pace of innovation, particularly at our scale, is unparalleled. With an annual R&D budget approaching $20 billion and our ability to perform extreme co-design across computing and networking, chips, systems, algorithms, and software, we aim to achieve an X-fold leap in performance per watt with every product generation and expand our leadership position over the long term.
Data center revenue for the fourth quarter was $62 billion, representing a year-over-year increase of 75% and a sequential increase of 22%, driven primarily by the continued strong momentum in the ramp-up of Blackwell and Blackwell Ultra production. Due to the high demand for NVIDIA infrastructure, even Hopper and many products based on the six-year-old Ampere architecture have sold out in the cloud. Nearly a year has passed since the launch of our Grace Blackwell NVL72 system. To date, major cloud service providers, hyperscale computing companies, AI model manufacturers, and enterprises have deployed and consumed nearly 9 gigawatts (GW) of Blackwell-based infrastructure.
Networking is the cornerstone of our data center-scale infrastructure offerings, and this quarter it delivered standout performance, generating $11 billion in revenue, more than 3.5 times higher than the same period last year. Demand for our scale-up and scale-out technologies reached record levels, with both achieving double-digit sequential growth, driven by strong adoption of NVLink, Spectrum-X Ethernet, and InfiniBand. On a year-over-year basis, growth was primarily driven by NVLink 72 scale-up switches, as Grace Blackwell systems accounted for approximately two-thirds of the quarter's data center revenue. The NVLink scale-up architecture has revolutionized computing and demonstrated the power of extreme co-design across all chips and the full stack in supercomputers.
In the fourth quarter, we announced that AWS would integrate NVLink technology with its custom chips. As customers work to unify distributed data centers into integrated gigawatt-scale AI factories, our Spectrum-X Ethernet scale-up and scale-out networking momentum remains robust. For the full year, our networking business revenue exceeded $31 billion, growing more than tenfold compared to fiscal year 2021 when we acquired Mellanox. Our demand profile is broad, diverse, and expanding beyond chatbots.
First, there has been a fundamental platform shift from traditional machine learning to generative AI. As hyperscale computing companies upgrade massive amounts of traditional workloads—including search, ad generation, and content recommendation systems—to generative AI, compelling return on investment (ROI) evidence is encouraging our largest customers to accelerate their capital expenditures. For example, at Meta, advancements in its generative (Gen / Llama) models have increased Facebook's ad click-through rate by 3.5% and Instagram's conversion rate by over 1%, translating into meaningful revenue growth. Leveraging the same NVIDIA infrastructure, Meta's Super Intelligence Lab can train and deploy its cutting-edge agent-based AI systems. Frontier agent systems have reached an inflection point.
Claude Code, Claude Cowork, and OpenAI Codex have achieved useful intelligence. Their adoption rates are soaring, and token generation is profitable, significantly driving the urgency to scale up compute capacity. Compute power directly translates into intelligence and revenue growth. Analyst expectations for the top five cloud service providers and hyperscale computing companies (who collectively account for just over 50% of our data center revenue) for capital expenditures in 2026 have risen by nearly $120 billion since the start of the year, approaching $700 billion.
We continue to expect that the transition of traditional data center workloads to GPU-accelerated computing, along with the trend of leveraging AI to enhance today’s hyperscale workloads, will contribute to about half of our long-term market opportunity. Every nation will build and operate part of its AI infrastructure, much like electricity and the internet today. In fiscal year 2026, our sovereign AI business grew more than threefold year-over-year, surpassing $30 billion, primarily driven by customers in Canada, France, the Netherlands, Singapore, and the UK. Over the long term, as countries spend proportionally on AI according to their GDP, we expect sovereign AI opportunities to grow at least in line with the expansion of the AI infrastructure market.
Although the U.S. government approved the shipment of a limited number of H200 products to Chinese customers, we have not yet generated any revenue, and we do not know whether any imports into China will be allowed. Our competitors in China have made progress supported by recent IPOs and have the potential to disrupt the global AI industry structure in the long run. To maintain its leadership in AI computing, the U.S. must attract every developer and become the preferred platform for all commercial enterprises, including Chinese companies. We will continue to engage with the U.S. and Chinese governments and advocate for America’s ability to compete globally.
Last month, we launched the Rubin platform at CES, which includes six new chips: Vera CPU, Rubin GPU, NVLink 6 switch, ConnectX-9 SuperNIC, BlueField-4 DPU, and Spectrum-6 Ethernet switch. Compared to Blackwell, this platform can train MOE models using only a quarter of the number of GPUs and reduce inference token costs by up to 10 times. Earlier this week, we shipped the first Vera Rubin samples to customers, and we are on track to begin volume shipments in the second half of this year. With its modular, table-free/cable-free design, Rubin will offer better resilience and maintainability than Blackwell. We expect every cloud model builder to deploy Vera Rubin.
Next, let’s look at the gaming business. Gaming revenue reached $3.7 billion, a year-over-year increase of 47%, driven by strong demand for Blackwell and improved supply. GeForce RTX is the leading platform for PC gamers, creators, and developers. In the fourth quarter, we introduced several new technologies and enhancements, including DLSS 4.5, which uses AI to elevate game visuals to new levels, G-SYNC Pulsar, which delivers incredibly sharp graphics even during motion, and a 35% boost in large language model (LLM) inference speed within leading AI PC frameworks. Looking ahead, while end-user demand for our products remains strong and channel inventory levels are healthy, we anticipate that supply constraints will pose headwinds in the first quarter and beyond.
Professional visualization revenue surpassed the $1 billion mark for the first time, reaching $1.3 billion, a year-over-year increase of 159% and a sequential increase of 74%. This quarter, we launched the RTX Pro 5000 Blackwell workstation equipped with 72GB of high-speed memory, designed for AI developers running large language models (LLMs) and agent-based workflows.
Automotive revenue was $604 million, a year-over-year increase of 6%, driven by strong demand for autonomous driving solutions. At CES, we introduced Alpamayo, the world’s first open product portfolio for inference vision-language-action models, simulation blueprints, and datasets, giving vehicles the ability to “think.” The first passenger vehicle equipped with Alpamayo, based on NVIDIA Drive, the new Mercedes-Benz CLA, is set to hit the road soon.
Physical AI has arrived, contributing over $6 billion in revenue to NVIDIA in fiscal year 2026. The volume of rides from driverless taxis (Robotaxis) is growing exponentially. Commercial fleets from companies like Waymo, Tesla, Uber, WeRide, Zoox, and many others are expected to expand from thousands in 2025 to millions in the next decade, creating a market poised to generate hundreds of billions of dollars in revenue. This expansion will require a tenfold increase in computing power, and all major OEMs and service providers are currently developing on NVIDIA's platform.
We continue to advance robotics development through the new NVIDIA Cosmos and Isaac Group, open models, frameworks, and NVIDIA-driven robots and autonomous machines, collaborating with leading companies such as Boston Dynamics, Caterpillar, Franka Robotics, LG Electronics, and Neuro Robotics. To accelerate the adoption of industrial physical AI, we also announced expanded partnerships with Dassault Systèmes, Siemens, and Synopsys, bringing NVIDIA’s AI infrastructure, Omniverse digital twins, world models, and CUDA-X libraries to millions of researchers, designers, and engineers to build the global industrial system.
Let’s review other parts of the income statement. GAAP gross margin was 75%, and Non-GAAP gross margin was 75.2%, achieving sequential growth as Blackwell production capacity continues to ramp up. GAAP operating expenses increased by 16% sequentially, while Non-GAAP operating expenses rose by 21% sequentially, primarily due to new product launches and increased computing and infrastructure costs. The fourth-quarter Non-GAAP effective tax rate was 15.4%, lower than our expectations for the quarter, mainly due to the impact of one-time tax benefits.
Inventory increased by 8% sequentially, and procurement commitments have significantly risen as we strategically secure inventory and production capacity to meet demand beyond the next few quarters. This forward-looking approach reflects our longer-term visibility into demand. While we expect tight supply conditions for advanced architectures to persist, our scale, extensive supply chain, and long-term partners' continued support give us confidence in our ability to seize upcoming growth opportunities.
We generated $35 billion in free cash flow in the fourth quarter and $97 billion in free cash flow in fiscal year 2026. During the year, we returned $41 billion to shareholders through stock repurchases and dividends, representing 43% of free cash flow. We will continue to invest in technology and ecosystems to foster market development, drive long-term growth, and ultimately deliver superior total shareholder returns compared to the market or peers. Importantly, in terms of investments, we will continue to execute strategic and disciplined processes and remain committed to returning capital to shareholders.
Now, let me discuss our outlook for the first quarter. Starting this quarter, we will include stock-based compensation expense (SBC) in our Non-GAAP results. Stock-based compensation is a fundamental component of our compensation plans, designed to attract and retain world-class talent.
First, let us look at revenue. Total revenue is projected to be $78 billion, plus or minus 2%. We anticipate that the majority of growth will be driven by data centers. Consistent with the previous quarter, our outlook does not assume any data center computing revenue from China. GAAP and Non-GAAP gross margins are expected to be 74.9% and 75%, respectively, with a margin of fluctuation of 50 basis points. For the full year, we expect the gross margin to remain at the midpoint level of around 75%. As we prepare for the transition to Vera Rubin, we will keep you updated on the latest developments.
GAAP and Non-GAAP operating expenses are projected to be approximately $7.7 billion and $7.5 billion, respectively, including $1.9 billion in stock-based compensation expenses. For the full year, we anticipate that Non-GAAP operating expenses will grow by approximately 40% year-over-year (low 40s), as we continue to invest in expanding opportunity areas. For the entire fiscal year 2027, excluding any discrete items and significant changes in the tax environment, we expect GAAP and Non-GAAP tax rates to range between 17% and 19%.
Next, I will hand over the call to Jensen Huang, who has a few words to share with us.
Jensen Huang This quarter, we significantly deepened and expanded our partnerships with leading frontier model developers. Recently, we celebrated the release of OpenAI's GPT 5.3 Codex, which was trained and used for inference on the Grace Blackwell NVLink72 system. GPT 5.3 Codex is capable of handling long-term tasks involving research, tool use, and complex execution. The 5.3 Codex has been widely deployed within NVIDIA, and our engineers love it. We continue to advance our cooperation agreement with OpenAI and believe we are close to finalizing it. We are excited about our ongoing collaboration with OpenAI, a once-in-a-decade company, and we are honored to have partnered with them since their inception.
Meta’s Super Intelligence Lab is scaling up at lightning speed. Last week, we announced that Meta is deploying millions of Blackwell and Rubin GPUs, NVIDIA CPUs, and Spectrum-X Ethernet systems for training and inference.
This quarter, we announced a partnership with Anthropic and made a $10 billion investment. Anthropic will conduct training and inference on Grace Blackwell and Vera Rubin systems. Anthropic's Claude Cowork agent platform is revolutionary, opening the floodgates for enterprise-level AI adoption. Driven by Claude Cowork and OpenAI Codex, computing demand is surging, and the 'ChatGPT moment' for agent-based AI has arrived.
With partnerships spanning Anthropic, Meta, OpenAI, and xAI, NVIDIA's extensive deployment across every cloud, and our ability to build full-stack AI infrastructure from the ground up or support it in the cloud, we are uniquely positioned to collaborate with frontier model builders at every stage—training, inference, and horizontal scaling of AI factories.
Finally, we recently signed a non-exclusive licensing agreement with Grok to access its low-latency inference technology and welcome a team of outstanding engineers to NVIDIA. As we did previously with Mellanox, we will leverage Grok's innovations to expand NVIDIA’s architecture, achieving new heights in AI infrastructure performance and value. We look forward to sharing more information at next month's GTC conference.
Alright, back to you. We will now move into the Q&A session. Operator, please open the line for questions.
Q&A Session
Operator Your first question comes from Vivek Arya of Bank of America Securities. Your line is now open.
Vivek Arya, thank you for taking my question. I believe you mentioned that you now have visibility into growth for the 2027 calendar year, and your procurement commitments seem to reflect that confidence. However, Jensen, I'm curious—when you look at your top cloud customers, this year the cloud industry's capital expenditure is nearing $700 billion, and many investors are concerned about the difficulty of sustaining growth at this level next year, with some also facing compressed cash flow generation. I know you're highly confident in your product roadmap and procurement commitments, but how confident are you in your customers' ability to continue increasing their capital expenditures? And if their capital expenditure doesn't grow, can NVIDIA still find growth within this framework? Thank you.
Jensen Huang: I am very confident in their cash flow growth for a very simple reason: we are now witnessing the inflection point of Agentic AI and the practical applications of agents across enterprises and regions worldwide. This is why you see an incredible demand for computing power.
In this new era of AI, computing equals revenue. Without computing, there is no way to generate tokens; without tokens, there is no way to achieve revenue growth. Therefore, in this new era of AI, computing is equivalent to revenue. I am quite certain that with Codex and Claude Code now in production, the excitement around Claude Cowork, combined with enthusiasm for OpenAI systems and their enterprise versions, as well as all enterprise-grade ISVs (independent software vendors) currently building agent-based systems on their tool platforms—we are at an inflection point. We've reached this turning point where we are generating tokens that bring productivity to customers and profits to cloud service providers.
So the simple logic, or way to think about it, is that the method of computing has changed. In the past, software ran on computers using a moderate amount of computing resources, with annual capital expenditures of about $300-400 billion. Now, this has shifted toward AI. In the realm of AI, in order to generate tokens, you need computational power, which directly translates into growth and directly converts into revenue.
Operator: Your next question comes from Joseph Moore of Morgan Stanley. Your line is open.
Joseph Moore: Fantastic, thank you. Congratulations on your results. You mentioned some strategic investments in Anthropic and potentially in OpenAI Core, while you also have partnerships with companies like Intel, Nokia, and Synopsys. Clearly, you are at the center of everything. Could you discuss the role these investments play? How do you view the balance sheet as a tool to expand NVIDIA’s position within the ecosystem and participate in this growth?
Jensen Huang: As you know, at the core of everything NVIDIA does is fundamentally our ecosystem, which is why everyone loves our business—the richness of our ecosystem. Nearly all startups worldwide are researching and developing on NVIDIA’s ecosystem and platform.
We are present in every cloud, every on-prem data center, and global edge devices and robotic systems. Thousands of native AI enterprises are built on NVIDIA. As we stand at the beginning of this new era of computing and this shift to a new computing platform, we want to seize this massive opportunity to make sure everyone uses NVIDIA. Everyone, everything, is already built on CUDA. So, we are starting from a fantastic position.
As we build out the entire AI ecosystem—whether it is AI for language, physical AI, physics AI, biology AI, robotics, or manufacturing AI—we want all these ecosystems to be built on NVIDIA. For us, this represents an excellent opportunity to invest in ecosystems throughout the technology stack.
Our ecosystem today is richer than ever before. In the past, we were primarily a GPU-based computing platform, but now we are a computing AI infrastructure company. We have a computing platform across all aspects—from computing to AI models, networking, and our DPUs, with a computing stack above all of them. As I mentioned earlier, whether in enterprises, manufacturing, industry, science, or robotics, each ecosystem has different technology stacks, and we want to ensure continued investment in these ecosystems. Therefore, our investments are explicitly and strategically focused on expanding and deepening our ecosystem coverage.
Operator, your next question comes from Harlan Sur of JPMorgan. Your line is now open.
Harlan Sur: Good afternoon, and thank you for taking my question. The networking business continues to grow as a percentage of your overall data center business. Throughout fiscal year 2026, your networking revenue growth has been accelerating quarter by quarter. As you mentioned, there was a 3.6x year-over-year increase in Q4, clearly driven by the strength of your scale-up and scale-out networking portfolio.
I recall that in the first half of last year, your annualized run rate on the Spectrum-X Ethernet switching platform was around $10 billion. It seems that in the second half of last year, this figure may have jumped to somewhere between $11 billion and $12 billion. Jensen, looking at your order book, especially with the launches of Spectrum-XGS and the upcoming 102T Spectrum 6 switching platform, what is the current run-rate trend for Spectrum? How do you see things shaping up by the end of this year?
Jensen Huang: As you know, we view ourselves as an AI infrastructure company. AI computing infrastructure includes CPUs, GPUs, and we invented NVLink, which allows us to scale up a single compute node into a massive compute server rack. We pioneered the concept of rack-level computing. What we deliver is not just a single compute node but entire racks of computers.
This scale-up system using NVLink switches then scales out via Spectrum-X and InfiniBand — both of which we support. Furthermore, we also use Spectrum-X to expand across data centers. Our approach to networking is essentially about extending capabilities. We provide everything openly so people can decide how to mix and match at different scales or integrate it into their customized data centers however they wish.
At the end of the day, this is all a significant part of our platform. The invention of NVLink truly turbocharged our networking business. Each rack is equipped with nine network switch nodes, each containing two chips internally. In the future, there will be even more.
So, the amount of switching we handle per rack is truly incredible. We are now also the largest networking company globally. If you look at the Ethernet space, we entered the Ethernet switching market about two years ago. I believe we are likely already the largest Ethernet networking company in the world today, and it will soon be officially recognized.
Spectrum-X Ethernet has been a home run for us. However, we remain open to any networking approach that people wish to adopt. Some prefer the low latency and scale-up capabilities of InfiniBand, which we will continue to support, while others favor integrating their networks across the data center using Ethernet. We've developed Ethernet functionality that aligns Ethernet with how data centers process artificial intelligence, and we’ve done exceptionally well in this regard.
Our Spectrum-X performance truly demonstrates this. When building a $10 billion or $20 billion AI factory, even a 10% difference (easily reaching 20%) in data center network efficiency and utilization translates directly into real savings. So, NVIDIA’s networking business is growing incredibly fast. I think this is simply because we are highly effective at building AI infrastructure, and the AI infrastructure business is growing at an astonishing pace.
Operator, your next question comes from CJ Muse of Cantor Fitzgerald. Your line is now open.
CJ Muse, good afternoon. Thank you for taking the question. Given the broader context of large window applications, Grok, and possibly the need to add specific decoding solutions, I am curious about how we should view your roadmap going forward. Should we expect that customized silicon tailored to workloads or specific customers will increasingly become a focus for NVIDIA? Particularly leveraging your shift towards 'die-to-die/dial-in' architectures? Thank you very much.
Jensen Huang: No, we do not think so. Everyone should hope to delay the use of die-to-die interconnects as much as possible.
The reason is that every time you cross a die-to-die interface, you add another layer of interface. Every time you cross an interface, you inevitably increase latency and unnecessarily add power consumption. We are not against die-to-die technology; in fact, we are already using it, but we try to use it only when there is no other choice. So, if you look at the Grace Blackwell architecture and the Rubin architecture, we use two giant chips that are reticle-limited and combine them, which reduces architectural crossing.
The losses from this interconnect (interface) will show up in the performance of our competitors' architectures. When people talk about NVIDIA, they often refer to our software advantage, but it is hard to distinguish where the credit goes—to the software or to the architecture. Our software is efficient because our architecture is excellent.
The CUDA architecture is undoubtedly more effective and efficient than any other computing architecture on the market, delivering higher floating-point operations per watt due to the way our architecture is designed.
As for how we view Grok and low-latency decoders, I have some great ideas that I look forward to sharing with you at GTC. But the simplest idea is this: thanks to CUDA, our infrastructure has incredible versatility, and we will continue to maintain this. All of our GPUs are architecturally compatible. This means that when I optimize models for Blackwell today, all the effort and investment in optimizing the software stack and new models will also benefit Hopper and Ampere. This is why, years after we deployed it, the A100 still feels new and performs exceptionally well.
Architectural compatibility allows us to achieve this. It enables us to make massive investments in software engineering and optimization because we know that the entire installed base of our GPU architectures—whether running in the cloud, on-premises, or anywhere else—will benefit.
We will continue to do this, as it allows us to extend the lifespan of our products and gives us flexibility and speed in innovation. This translates into performance for our customers and, importantly, into performance per dollar and performance per watt. So, regarding what we will do with Grok, you will find out at GTC. What we will do is use Grok as an accelerator to expand our architecture, similar to how we expanded NVIDIA's architecture with Mellanox.
Operator: The next question comes from Stacy Rasgon of Bernstein Research. Your line is now open.
Stacy Rasgon: Hello everyone, thank you for taking my question. Colette, I would like to dive deeper into the expectation for year-over-year growth. Your data center business grew by over $10 billion quarter-over-quarter this quarter, and the guidance seems to suggest that this momentum will continue. As we move through the year, especially as Rubin begins to ramp up during this interval, how do you see this trend playing out? Blackwell has driven a very significant acceleration in quarter-over-quarter growth. Should we expect something similar when we transition to Rubin? Additionally, I would like you to discuss expectations for the gaming business. I understand memory constraints and everything else. Do you believe the gaming business can still achieve year-over-year growth in fiscal year 2027, or will memory issues put greater pressure on it? Please address both questions. Thank you.
Colette Kress Thank you, Stacy. Let me start with the future revenue. We try to look at revenue on a quarterly basis.
When thinking about the entire year, there is no doubt that we will continue to sell and deliver Blackwell, and at the same time, we see Vera Rubin entering the market. This is an excellent architecture that can immediately help them quickly build systems. We have planned many different orders for this product across multiple customers. It is currently uncertain how much of Vera Rubin’s ramp in the early part of the second half will contribute, but there is no doubt that demand and interest are very strong.
We expect almost every customer to purchase Vera Rubin. The question is simply how fast we can bring it to market and how quickly they can deploy it in their respective data centers. That was the first part of your question.
The second part pertains to our gaming business. Although we wish we could supply more, we do believe that supply will remain very tight over the next few quarters. If conditions improve by the end of the year, there may be opportunities from a year-over-year growth perspective. However, it is still too early to determine, and once we have clearer information, we will update you as soon as possible.
Operator Your next question comes from Atif Malik at Citi. Your line is now open.
Atif Malik Thank you for taking my question. Jensen, I am curious if you could talk about the critical role CUDA plays as more AI investments flow into inference workloads.
Jensen Huang Without CUDA, we would be lost when it comes to inference. The entire technology stack – starting with TensorRT LLM, which we introduced a few years ago and remains the highest-performing inference stack in the world – required us to discover and invent new parallelization algorithms built on CUDA to distribute workloads and perform inference, optimizing it for NVLink to fully leverage the aggregated bandwidth across NVLink 72.
NVLink 72 enables us to achieve a generational leap of 50 times better performance per watt. This is an incredible leading advantage and a wise move. NVLink 72 is a great invention, and it was extremely difficult to implement. Developing this switching technology, decoupling the switches, building system racks, and all of this was done in the public eye, and everyone knows how challenging it was for us. But the results are incredible: 50 times better performance per watt and 35 times better performance per dollar. Thus, the leap in inference capabilities is absolutely astonishing.
It is very important to recognize that for our customers, inference equals revenue. Intelligent agents generate such a vast number of tokens, and the results are highly effective. When intelligent agents write code, they generate thousands, tens of thousands, or even hundreds of thousands of tokens because they run for minutes to hours. These agent-based systems spawn different agents working collaboratively as teams. The number of tokens being generated is truly, truly growing exponentially.
So we need to perform inference at a faster pace. When you conduct inference faster and each of these tokens is priced in dollars, it directly translates into revenue.
Therefore, for our clients, inferencing performance is equivalent to revenue. For data centers, the number of tokens per watt of inferencing directly translates into income for cloud service providers (CSPs). The reason is that everyone's power supply is constrained. No matter how many data centers you have, whether it’s 100 megawatts or 1 gigawatt, there are power limitations. Thus, having the architecture with the best performance per watt translates into revenue because the number of tokens generated per watt—where every token is monetized—converts into dollar output per watt. At the gigawatt scale, this directly determines the scale of revenue.
You can see now that every CSP and every hyperscaler understands this: capital expenditure translates into compute power. Having the right architectural compute power means maximizing revenue; compute equals revenue. Without investing in capacity and compute power today, revenue growth cannot be achieved. I think everyone understands this. Choosing the right architecture is extremely critical—not only is it strategically important, but it also directly impacts their profitability. Choosing the right architecture—with the best performance per watt—really means everything.
Operator Your next question comes from Ben Reitzes at Melius Research. Your line is open.
Ben Reitzes Hello, thank you. First, let me commend you on including stock-based compensation in your Non-GAAP results. I think that’s a great move. But that’s not my question.
My question relates to gross margins and their sustainability at around 75% over the long term. Does the visibility into supply extending into the calendar year 2027 allow us to interpret that these gross margins are sustainable until then? Additionally, Jensen, what happens beyond that? Can you demonstrate innovations in memory consumption that would give us more confidence in maintaining these gross margins at this level in the long run? Thank you.
Jensen Huang The most important factor affecting our gross margin is actually whether we can deliver generational leaps in performance for our customers. That is the single most important thing.
If we can achieve generational leaps in performance per watt, far exceeding the pace of Moore's Law, and if we can offer exceptionally high performance per dollar, far surpassing the cost and pricing of our systems, then we can continue to maintain our gross margin. It’s the simplest and most crucial concept.
The reason we are growing so quickly is that the world has reached several inflection points where demand for tokens has grown exponentially. I think we all see this. To the extent that even our GPUs deployed in the cloud six years ago have been fully consumed, and pricing continues to rise. So we know that the computational demands of modern software development are increasing exponentially.
Therefore, our strategy is to deliver a complete AI infrastructure solution every year. This year, we introduced six new chips (Rubin platform), and in the next generation, we will also roll out many new chips. With each generation, we focus on delivering an X-fold leap in performance per watt and performance per dollar. This pace, combined with our ability to engage in extreme co-design, allows us to pass this value and benefit on to our customers. As long as it pertains to the value we deliver, this is the most critical aspect.
Operator Your next question comes from Antoine Chkaiban at New Street Research. Your line is open.
Antoine Chkaiban, hello, and thank you for taking the question. I would like to ask about the concept of 'space data centers,' which some of your clients are reportedly considering. How feasible do you think this idea is? What is the timeline? What is the current economic viability? And how do you see it evolving over time? Thank you.
Jensen Huang: Well, the economic viability today is quite poor, but it will improve over time. As you know, the way things operate in space is very different from how they work on Earth. There is abundant energy in space, requiring massive solar panels, but there is also ample room.
In terms of heat dissipation, while space is cold, there is no airflow. Therefore, the only way to dissipate heat is through conduction. The radiators you would need to build would have to be quite large. Liquid cooling is obviously not an option because it is heavy and would freeze. So, the methods we use on Earth differ from what would be applied in space. However, there are many computational challenges that are well-suited for processing in space.
NVIDIA already has the world's first space GPU, and Hopper is currently in space. One of the best use cases for GPUs in space is imaging. In space, leveraging optical technologies and artificial intelligence, it is possible to perform imaging at extremely high resolutions, calculate projections from different angles, enhance resolution, and reduce noise, delivering visual capabilities for rapid imaging at very high resolutions and large scales. It is very challenging to accomplish this on Earth by transmitting petabytes of imaging data. Processing directly in space is much easier.
You can ignore all the data collected during processing that turns out to be irrelevant, and only transmit back when something interesting is detected. Therefore, artificial intelligence will have highly impressive and fascinating applications in space.
Operator: Your next question comes from Mark Lipacis of Evercore ISI. Your line is open.
Mark Lipacis: Hello, and thank you for taking my question. I would like to follow up on the topic of revenue diversification discussed in the briefing. I believe, Colette, you mentioned that hyperscale computing companies account for more than 50% of your revenue, but growth is being driven by the remaining data center customers. I just wanted to clarify to ensure I understood correctly.
Does this mean that non-hyperscale customers are growing faster? If so, could you help us understand what non-hyperscale customers are doing differently? Are they engaging in different activities compared to hyperscale customers, or are they doing similar things but on a different scale? Do you believe this trend will continue? And do you anticipate your customer base evolving to a point where non-hyperscale customers become a larger portion of your business? Thank you.
Colette Kress: Alright, let’s see if we can address that. When you consider the top five CSPs (cloud service providers) and hyperscale computing companies we mentioned, they currently account for about 50% of our total revenue. However, beyond that, there is a wide variety of organizational forms with significant diversity, including AI model builders, enterprise users, supercomputing institutions, and our sovereign AI clients, as well as many other different sectors. You're absolutely correct.
This is also a rapidly growing area. Not only do we have a strong presence across various cloud provider platforms, but we are now seeing an extremely diverse customer base worldwide. Being able to recognize this diversity and serve all these different groups will greatly benefit us. Let’s see if Jensen wants to add anything further.
Jensen Huang Yes, this is one of the advantages of our ecosystem built on CUDA.
We are the only accelerated computing platform that is present in every cloud, available through every computer manufacturer, and usable at the edge. We are now also cultivating the telecommunications sector. Clearly, future radios will be AI-driven, and future wireless networks will become a computing platform. This is an undeniable conclusion, but someone has to invent the relevant technologies to make it happen. We have created a platform called Aerial for this purpose. Our technology is integrated into almost every robot and every autonomous vehicle. CUDA can achieve the performance benefits of a dedicated processor via Tensor Cores within the GPU while maintaining immense flexibility, enabling us to address problems ranging from language issues, computer vision challenges, robotics, biology, physics, and nearly all kinds of AI and computational algorithms.
Thus, the diversity of our customer base is one of our greatest strengths. The second point, of course, is that even if our processors are programmable, without fostering our own ecosystem (as we discussed regarding investing in and continuing to strengthen the future ecosystem), it would be difficult for us to break through the limitation of merely securing a few design wins within someone else’s ecosystem. Thanks to the platform we have created, we can grow and expand our ecosystem very naturally.
Lastly, a very important point is our partnerships with OpenAI, Anthropic, XAI, and Meta. Of course, there are also nearly all open-source projects worldwide. There are 1.5 million AI models on Hugging Face, and all of them run on NVIDIA CUDA. If you add up all the open-source models, they may represent the second-largest collection of models in the world (OpenAI being the largest, and the aggregate of all open-source models potentially the second largest). NVIDIA's ability to run all of these makes our platform highly fungible, extremely user-friendly, and worthy of investment confidence. This creates both customer diversity and platform diversity, and because we support a global ecosystem, it can be utilized in every country/region.
Operator Your next question comes from Aaron Rakers of Wells Fargo & Co. Your line is now open.
Aaron Rakers Hello, thank you for taking my question. I’d like to follow up on the concept of platform and extreme co-design. Some news from the last quarter indicated that NVIDIA has the capability or is pushing to bring the Vera CPU to market as an independent solution. Jensen, I am curious about the significant role Vera plays in the evolution of your architecture. Is this driven by the proliferation or heterogeneity of inference workloads? I’m curious about how you view its role in NVIDIA’s development, especially in the form of an independent CPU. Thank you.
Jensen Huang Yes, thank you for the question. I will tell you more details at the GTC conference. But at the highest level, we made fundamental architectural decisions with our CPU that differentiate it entirely from other CPUs in the world. It is the only data center CPU that supports LPDDR5, designed with a focus on extremely high data processing capabilities.
The reason is that most of the computing problems we are interested in are data-driven, and artificial intelligence is one of them. Vera excels in the ratio of single-threaded performance to bandwidth. We made these architectural decisions because the entire AI pipeline and its various stages (before training, you must process the data) cover data processing, pre-training, and now post-training. AI is now learning how to use tools.
Many tools operate in environments with only CPUs or in environments combining CPUs with GPU acceleration. Vera is designed to be an exceptional CPU for the post-training phase. Therefore, some use cases in the entire AI pipeline include heavy usage of CPUs. We love GPUs as much as we love CPUs.
When you push algorithm acceleration to the limit as we do, Amdahl's Law indicates that you need extremely fast single-threaded CPUs. This is why we built the Grace architecture to excel in single-threaded performance, and Vera's performance is even more remarkable than that.
Operator: Your next question comes from Tim Arcuri of UBS Group. Your line is now open.
Tim Arcuri: Thank you very much. Colette, I would like to ask if you could talk about the issue of capital deployment. I understand that you have significantly increased the scale of your procurement commitments, and it seems that you may have passed the peak period of investment. Additionally, this year you might generate approximately $100 billion in cash. However, regardless of how good the performance is, the stock price doesn't seem to have risen much. Therefore, I believe you might feel that the current price level represents a fairly attractive opportunity for repurchasing a large number of shares.
I would like to know if you could discuss this. The question is, why not set an ambitious goal and conduct a large-scale share buyback at this point? Thank you.
Colette Kress: Thank you for your question. We are very cautious in reviewing our capital return plans. We firmly believe that one of the most important things we can do is truly support the vast ecosystem in front of us. This covers everything: from our suppliers, to the work required to secure the supply chain and help them increase production capacity, all the way to early developers creating AI solutions on our platform.
Therefore, we will continue to treat this (investing in the ecosystem) as a very important part of our processes and strategic investments. Of course, we are still repurchasing our shares. We also continue to pay dividends. Throughout the year, we will continue to look for specific opportunities to execute these repurchases.
Operator: Your final question comes from Jim Schneider of Goldman Sachs. Your line is now open.
Jim Schneider: Thank you for taking my question. Jensen, you previously outlined that data center capital expenditure could reach $3 trillion to $4 trillion by 2030, implying that growth rates may accelerate, which you also hinted at in the guidance for the next quarter. My question is, what do you think are the key applications most likely to drive this inflection point? Is it physical AI, agent-based AI, or something else? And do you still feel confident about the $3 trillion to $4 trillion market projection? Thank you.
Jensen Huang: Yes, let’s take a step back and reason through this from several different perspectives.
First, from first principles. The future method of developing software will be AI-driven software. Using AI is token-driven. I think everyone is talking about tokenomics, discussing data centers generating tokens; the essence of inference is generating tokens. We are generating tokens. We just mentioned how NVIDIA's NVLink72 enables us to generate tokens with 50 times higher performance per unit of energy consumption compared to the previous generation. Thus, looking ahead, token generation will be at the center of almost everything related to software and computing.
Reflecting on how we used computation in the past, the amount of computation required by software back then was only a fraction of what will be needed in the future. AI is here, and it will not regress; AI will only get better and better. So, if you think about it, the world used to invest around $300 billion to $400 billion annually in classical computing. Now that AI has arrived, the computational demands are a thousand times greater than what we required with our previous methods of computing. The demand for computing power is vastly higher. As long as we continue to believe there is value in this (which we will discuss later), the world will invest in computing power to produce these tokens. Therefore, the world’s need for token generation far exceeds what $700 billion can cover.
I am quite confident that from this point forward, we will continue to generate tokens, and we will continue to invest in computing power. Fundamentally, every company relies on software, and every piece of software will depend on AI. Therefore, every company will produce tokens. This is why I refer to them as 'AI factories.' If your company operates within cloud data centers, you possess AI factories that generate tokens for revenue; if you are an enterprise software company, you will generate tokens for agent-based systems on your tools; if you are a robotics manufacturer (with autonomous vehicles being one of the earliest manifestations), you will have massive supercomputers (essentially AI factories) generating tokens to serve as the AI brain for your vehicles. Then, you must also embed computers in the cars to continuously generate tokens.
Therefore, we are now very certain that this is the future of computing.
So, why are we so certain that this is the future of computing? The reason lies in how we used to create software: it was pre-recorded. Everything was captured a priori. We precompiled software, pre-wrote content, and pre-recorded videos. But now, everything is generated in real-time. When generated in real-time, it can take into account a person’s background, their context, the content of their queries, and their intent to produce results for this new type of software known as AI (or agent-based AI). Consequently, it requires far, far more computing power than pre-recorded methods. Just as computers possess significantly more computing power than DVD players that play pre-recorded content, artificial intelligence demands far greater computational capacity than our previous approaches to software creation.
Regarding the sustainability of computing, first at the level of computer science, this will be the way computing evolves in the future.
Secondly, at the industry level. Ultimately, all companies are driven by software, and cloud service companies are no exception. If new software requires generating tokens, and these tokens can be monetized, then it naturally follows that the construction of their data centers will directly drive their revenue. Computing drives revenue, and I believe they understand this. Moreover, I think the external world is increasingly beginning to grasp this reality.
Finally, the benefits AI creates for the world must eventually translate into revenue. We are witnessing this unfold, as we are now at a turning point for agent-based AI. This has actually occurred over the past two to three months. Of course, within the industry, we have seen this trend for some time—about six months—but now the entire world has awakened to the inflection point of agent-based AI. Agents are exceptionally intelligent and are solving real-world problems. Programming work is clearly now assisted by agent-based systems. All programmers within NVIDIA extensively use agent-based systems, whether it’s Claude Code, OpenAI Codex, or Cursor, often employing all three depending on the use case. However, they have agents and collaborative design engineering partners to help them solve problems.
You can see the revenue of these companies skyrocketing. Take Anthropic, for example—I believe their revenue grew tenfold in a year, and they are severely constrained by capacity because the demand is simply incredible. The demand for tokens is overwhelming, with token generation rates growing exponentially. OpenAI is in the same situation, facing astonishing demand. Therefore, the more computing power they can build and bring online, the faster their revenue grows.
This brings me back to my earlier point: inference equals revenue. In this new world, computing equals revenue. In many ways, this is why we say this is a new industrial revolution.
New factories, new infrastructure are being built, and this new mode of computing will not regress. Therefore, as long as we believe that generating tokens represents the future of computing—and I firmly believe this, as does much of the industry—then from this point forward, we will continue to build this capability and expand from here.
The wave we are currently experiencing is the explosion of agent-based AI; the next inflection point after this will be the integration of physical AI and these agent systems into physical applications such as manufacturing and robotics. Thus, there are immense opportunities ahead.
Analyst: Thank you.
Operator: The Q&A session has now concluded. I will now hand the conference back to Toshiya Hari.
Toshiya Hari: As we conclude today’s meeting, please note that Jensen Huang will participate in a fireside chat at the Morgan Stanley TMT (Technology, Media, and Telecommunications) Conference in San Francisco on March 4. He will also deliver a keynote speech at the GTC Conference in San Jose on March 16. Our earnings call to discuss the first quarter of fiscal year 2027 is scheduled for May 20. Thank you all for joining us today. Operator, please conclude the conference.
Operator: Thank you. This concludes today's conference call. You may now disconnect. The conference has ended.
 Earnings Express has been fully upgraded, giving you an edge in investment discovery! Instructions: Open Futubull > Individual Stock Page > Click on the [Company] Tab >Earnings Express
Earnings Express has been fully upgraded, giving you an edge in investment discovery! Instructions: Open Futubull > Individual Stock Page > Click on the [Company] Tab >Earnings Express
Editor/Doris