
NVIDIA will integrate LPU technology to launch a new inference chip, with OpenAI heavily investing to follow suit, marking the shift of the main AI computing battleground from training to inference. Shenwan Hongyuan Research points out that the era of inference is driving four emerging trends: increased deployment scenarios for CPUs, the rise of LPU-specific architectures, accelerated breakthroughs for domestic chips, and the transition of computing demand from training to massive token consumption. As chips move towards a division of labor between training and inference, and systems evolve into three-layer architectures, cost-effective inference chip manufacturers will emerge as the biggest beneficiaries.
$NVIDIA (NVDA.US)$ The integration of LPU (Language Processing Unit) technology and OpenAI's diversified investment in inference chips is shifting the primary battleground of AI computing power from training to inference. Shenwan Hongyuan Research predicts that the core keyword for the computing power industry in 2026 will be inference, with total Token consumption and technological paradigms undergoing profound restructuring around this theme.
On February 28, according to a report by The Wall Street Journal, NVIDIA plans to unveil a new inference chip incorporating Groq's 'Language Processing Unit' (LPU) technology at the GTC Developer Conference next month. Jensen Huang, CEO of NVIDIA, described it as an entirely new system 'the world has never seen before.' OpenAI has agreed to become one of the largest customers for this processor and will purchase large-scale 'dedicated inference capacity' from NVIDIA.
 At the same time, last month OpenAI also reached a multi-billion-dollar computing collaboration with startup Cerebras, which claims its inference chips outperform NVIDIA's GPUs (Graphics Processing Units). These developments indicate that AI giants are transitioning from an arms race in training computing power to a multi-pronged deployment in inference computing power.
At the same time, last month OpenAI also reached a multi-billion-dollar computing collaboration with startup Cerebras, which claims its inference chips outperform NVIDIA's GPUs (Graphics Processing Units). These developments indicate that AI giants are transitioning from an arms race in training computing power to a multi-pronged deployment in inference computing power.
The Shenwan Hongyuan report highlights four major trends in inference computing power in the Token economy era: First, the increasing adoption of pure CPU (Central Processing Unit) deployment scenarios, with low-cost inference demands accelerating the decentralization of computing power; second, the rise of specialized architectures such as LPUs, challenging the dominance of GPUs in inference tasks; third, domestic computing power chips achieving breakthroughs, with clear trends toward supply chain diversification; and fourth, a shift in the demand structure for inference computing power from 'single training sessions' to 'massive Token consumption,' making cost-effectiveness the core competitive factor.
The report notes that vendors capable of providing abundant, cost-effective inference chips will benefit the most, while breakthroughs in CPUs, LPUs, and domestic chips are shaping the core dynamics of this round of reshaping in the computing power landscape.
Inference demand is exploding comprehensively, with Token consumption reaching record highs.
Shenwan Hongyuan Research attributes the sustained expansion of demand to two structural drivers: First, the accelerated monetization of large models, with models like Claude beginning to penetrate application endpoints by launching multiple industry plugins; second, the acceleration of Agent deployments, with products like openclaw and Qwen Agent marking Agents entering real work and production scenarios, each requiring substantial inference computing power for every model invocation and Agent task execution.
Citing data during the Spring Festival, Shenwan Hongyuan Research noted a significant increase in inference throughput for leading domestic large models: DouBao achieved an inference throughput of 63.3 billion tokens on New Year’s Eve, Yuanbao reached 114 million monthly active users, and Qwen’s 'Spring Festival Mega Giveaway' event attracted over 120 million participants.
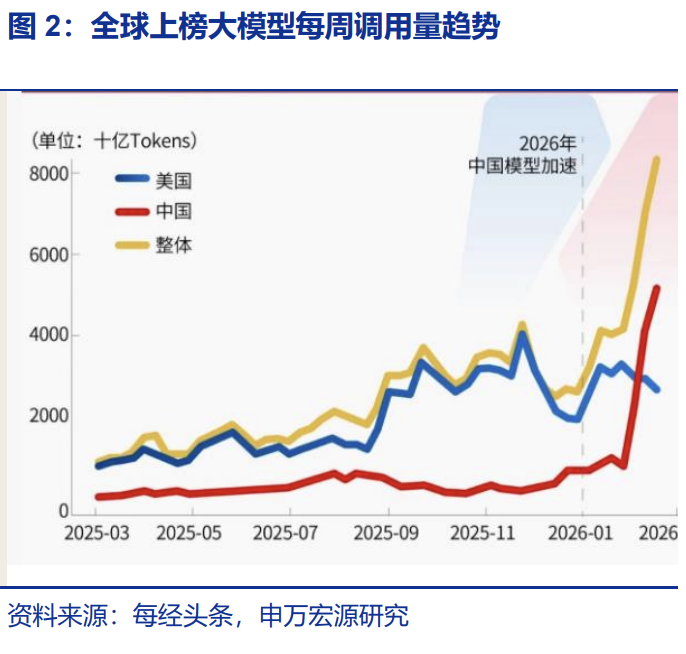
Data from OpenRouter, a global AI model API aggregation platform, further reveals the magnitude of this trend. During the week of February 9 to 15, Chinese models surpassed U.S. models for the first time, with 4.12 trillion Tokens processed compared to 2.94 trillion Tokens for U.S. models; in the following week of February 16 to 22, Chinese model usage surged further to 5.16 trillion Tokens, a 127% increase over three weeks, with China occupying four of the top five spots globally in terms of usage volume.
LPUs are emerging as the new powerhouse, driving the divergence between training and inference chips.
NVIDIA has invested $20 billion to acquire a core technology license from Groq and absorbed its executive team, including founder Jonathan Ross, through a 'core hiring' deal. Shenwan Hongyuan Research believes that this transaction marks the formal recognition by top players of the significance of pure inference chips.
The architectural differences between LPU and traditional GPU are the fundamental reason for its efficiency advantages in inference scenarios. AI inference is divided into two phases: pre-filling and decoding, with the decoding process of large models being particularly slow. LPU specifically optimizes for the two major inference bottlenecks: latency and memory bandwidth. According to previous reports by Wall Street News, NVIDIA’s upcoming product release may involve the next-generation Feynman architecture, potentially adopting broader SRAM integration or even deeply integrating LPU using 3D stacking technology.
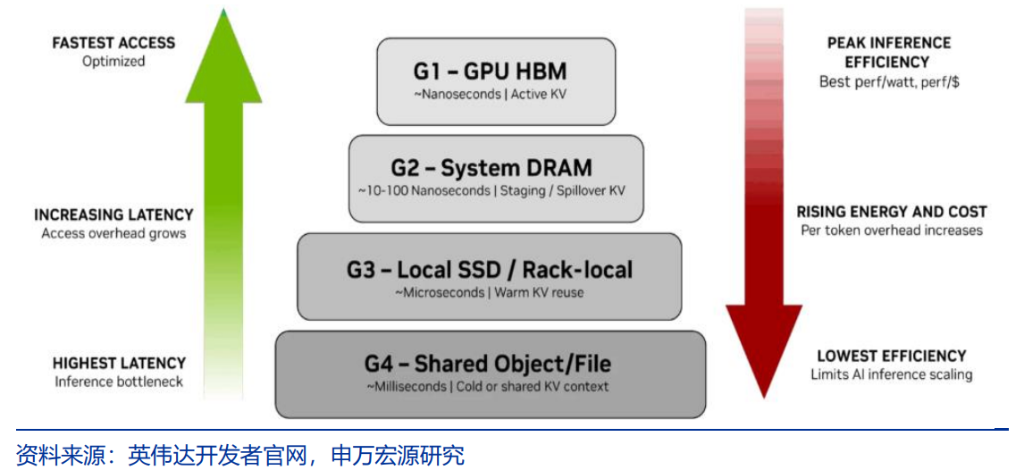
Shenwan Hongyuan Research predicts that the future AI chip market will see a clear division of technical roles: the training segment will continue to use the GPU-HBM combination, while the inference segment will evolve into an ASIC+LPU-SRAM+SSD solution. As computational demand shifts from training to inference, companies specializing in inference chips will encounter significant growth opportunities.
Comprehensive innovation in inference systems boosts CPU and networking requirements simultaneously.
The transformation from individual chips to system-level innovation represents another crucial dimension of this round of inference computing upgrades. Shenwan Hongyuan Research notes that as application scenarios shift from chatbots to Agents, the demands on latency, throughput, and reasoning depth increase simultaneously, driving the system architecture toward a three-layer network evolution.
The first layer is the fast-response layer, where pure inference chips equipped with SRAM provide ultra-low-latency feedback; the second layer is the deep-thinking layer, utilizing high-throughput computing clusters to handle complex logic reasoning, significantly increasing the demand for multi-core and multi-threaded CPUs in this layer; the third layer is the memory layer, corresponding to NVIDIA’s ContextMemory System, which manages long-term memory and KV Cache of Agents via SSD storage managed by Bluefield4 DPU.
NVIDIA is also adjusting its hardware strategy. The previous standard practice of bundling Vera CPUs with Rubin GPUs has proven too costly for specific AI agent workloads. This month, NVIDIA announced an expanded collaboration with Meta Platforms, completing its first large-scale pure CPU deployment to support Meta’s ad-targeting AI agents, marking the company's move beyond a single GPU sales model.
Accelerated breakthroughs in domestic computing power.
Shenwan Hongyuan Research believes that technological upgrades in domestic inference chips deserve close attention and present market expectation gaps.
At the technical level, the new generation of domestic inference chips achieves several fundamental improvements: added support for low-precision data formats such as FP8/MXFP8/MXFP4, with computing power reaching 1P and 2P respectively; significantly enhanced vector computing power with a new homogeneous design supporting both SIMD/SIMT dual programming models; interconnect bandwidth increased 2.5 times compared to the previous generation, reaching 2TB/s.
Particularly noteworthy is the achievement of PD separation at the chip level: through the in-house development of two different specifications of HBM, the PR version tailored for Prefill and recommendation scenarios, as well as the DT version for Decode and training scenarios, have been created. The PR version adopts low-cost HBM, significantly reducing investment costs during the Prefill phase of inference. It is expected to be launched in Q1 2026.
At the supply chain level, progress made by domestic packaging and testing manufacturers provides supporting evidence. According to the initial inquiry response letter from a leading packaging and testing company, its revenue from 2.5D packaging services primarily stems from high-performance computing chip packaging services. This revenue surged from RMB 0.5 billion in 2022 to RMB 18.2 billion in 2024, indirectly confirming the continuous improvement in the supply capacity of domestic computing chips and the acceleration of localization in the supply chain.
Editor/Lambor