
After Zhipu AI released GLM-5.2, researcher Teortaxes estimated that Chinese models would need seven months to catch up to Fable-level models. GLM-5.2 scored 74.4 on the FrontierSWE benchmark, trailing Opus 4.8 by approximately one percentage point. Domestically developed open-source models, leveraging advantages in performance, cost, and autonomy, are reshaping the global AI competitive landscape.
Following the export controls and subsequent delisting of Anthropic's cutting-edge models, a public debate over the timeline for China's large AI models to catch up is unfolding on X, with clashing viewpoints reflecting the accelerating realignment of the AI industry landscape.
on$KNOWLEDGE ATLAS (02513.HK)$On June 18, following AI's release of GLM-5.2, an X user asked independent researcher and AI development blogger Teortaxes, "When will China's large language models reach Fable-level capability?"
 Teortaxes estimated a gap of seven months, to which Elon Musk promptly replied, "Possibly Q1 [2027]," while Tang Jie, CEO of Zhipu AI, directly stated, "It won’t take that long."
Teortaxes estimated a gap of seven months, to which Elon Musk promptly replied, "Possibly Q1 [2027]," while Tang Jie, CEO of Zhipu AI, directly stated, "It won’t take that long."
Musk later added that catching up on benchmark tests is relatively easy, but measured by "real-world utility," achieving such performance by Q1 next year would already be impressive.
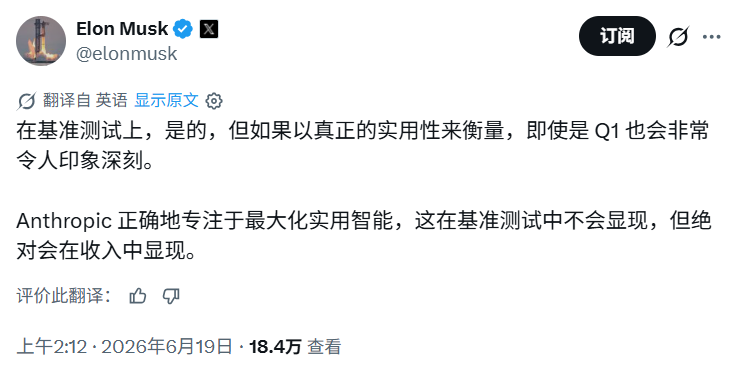
This exchange occurred against the backdrop of GLM-5.2 scoring 74.4 on the critical programming benchmark FrontierSWE—just about one percentage point behind Anthropic’s top-tier closed-source model Opus 4.8—and surpassing GPT-5.5.

As Caixin Global previously reported, the U.S. Department of Commerce imposed export controls on Anthropic’s Fable 5 and Mythos 5, requiring government licenses before granting access to any foreign nationals. In response, Anthropic immediately revoked global access to both models.
Two forces—technological catch-up and AI cost dynamics—are simultaneously reshaping the global AI competitive landscape. As ZeroHedge noted, when a "10% intelligence gap" may correspond to a "90% cost advantage," whether the allocation of over $5 trillion in capital represents a misallocation will remain a central question for markets.
The Timeline Debate: From Seven Months to "Not That Long"
The debate originated from Teortaxes’ assessment of GLM-5.2’s performance position.
He argued that GLM-5.2’s overall capability falls within the range of Opus 4.7 to 4.8, noting that Opus itself has relatively weak visual capabilities; accounting for vision performance, he estimated the gap for Chinese large models to be roughly seven months.
His reasoning is that the Mythos model will reach Preview status (i.e., achieving functionality equivalent to or exceeding Opus 4.8) by early February 2026, implying that Chinese models would reach full "Fable"-level capability sometime between November and December 2026.
Musk’s assessment was more conservative, responding only with "Probably Q1," corresponding to the first quarter of 2027.
However, he subsequently added an important distinction: while progress on benchmark tests may indeed be impressive, achieving genuine practical utility—even by Q1—would already be a significant accomplishment.
He highlighted that Anthropic’s advantage lies precisely in its focus on enhancing real-world intelligence—a capability not reflected in benchmark scores but directly evident in revenue.
Some AI industry insiders noted that Musk’s forecast appears relatively conservative, suggesting the time gap between Chinese and U.S. models could be shorter than seven months.
$Alphabet-C (GOOG.US)$DeepMind CEO Demis Hassabis previously stated that Chinese artificial intelligence models might be only "a few months behind" their overseas counterparts in capability.
Tang Jie offered a more concise and direct response: "won't take that long"—implying Zhipu AI’s confidence in its own iteration speed, though without specifying an exact timeline.
AI research firm Proximal remarked that GLM-5.2 is "the first model that has genuinely narrowed the vast technological gap between Anthropic/OpenAI and other model providers."
Technical positioning of GLM-5.2: approaching the closed-source frontier, yet a gap remains
Amid this debate over timelines, the technical specifications of GLM-5.2 serve as the central basis for evaluation.
On June 15, Zhipu AI announced the official launch and open-sourcing of its new flagship large language model, GLM-5.2. On Code Arena—a front-end development evaluation system featuring blind testing by over one million global users—the model ranked first among all publicly available models worldwide.
Unlike previous models that primarily focused on instant question-answering capabilities, GLM-5.2 is specifically optimized for 'long-horizon tasks'—enabling AI to work continuously for hours and autonomously complete an entire large-scale engineering project, much like a human would.
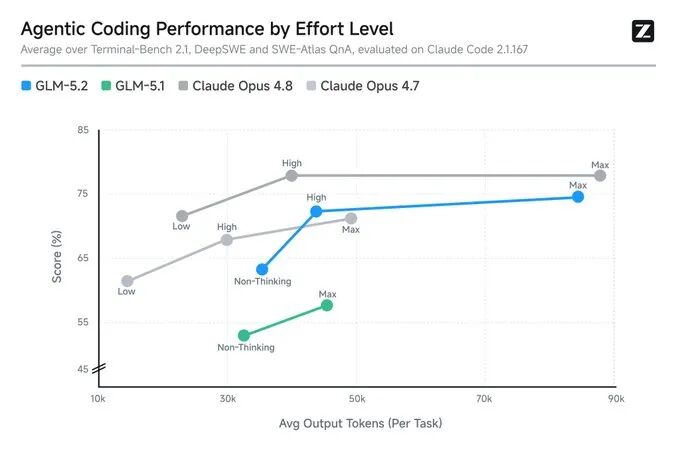
According to the release data, GLM-5.2 has 753 billion parameters, features a stable context window of 1 million tokens, and is fully open-sourced under the MIT license.
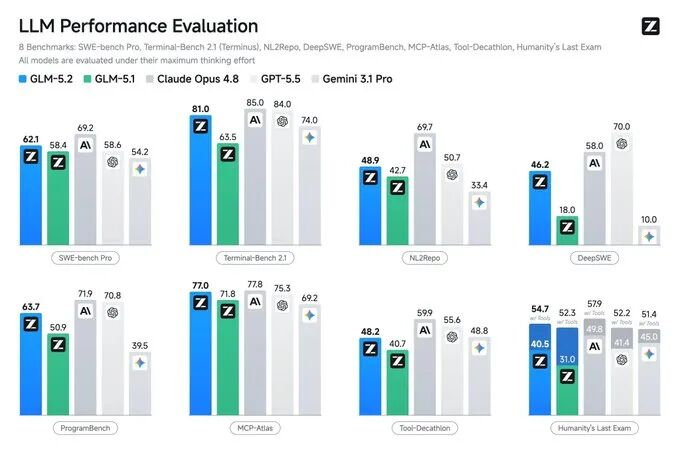
On the long-horizon programming benchmark FrontierSWE, GLM-5.2 scored 74.4, compared to Opus 4.8’s 75.1—a gap of approximately one percentage point—and outperformed both GPT-5.5 (72.6) and Opus 4.7.
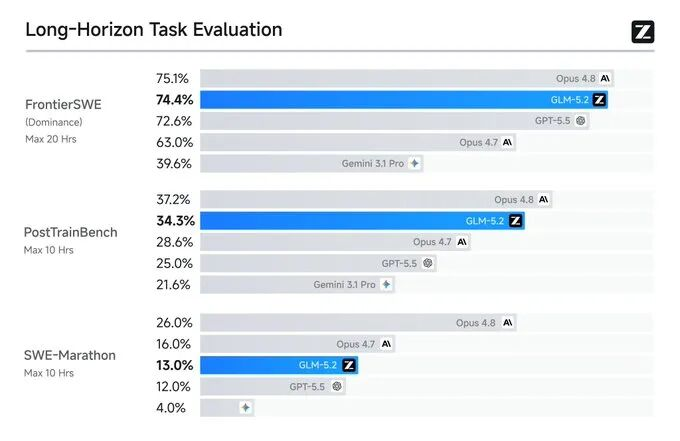
On PostTrainBench—which evaluates an agent’s ability to train smaller models—GLM-5.2 ranked second with a score of 34.3, trailing only Opus 4.8 (37.2) and surpassing GPT-5.5 (28.4).
A performance gap remains. On the most challenging SWE-Marathon benchmark, GLM-5.2 scored 13.0, significantly behind Opus 4.8’s 26.0.
Taken together, these three benchmarks convey a clear message: on moderately complex long-horizon tasks, GLM-5.2 has entered the competitive arena alongside top-tier closed-source models; while it still lags on the most extremely complex tasks, it leads decisively within the open-source ecosystem.
Anthropic models taken offline accelerates the case for open-source alternatives
Another key driver of this discussion is the sudden deprecation of Anthropic’s Fable 5 and Mythos 5 models.
As noted by Wall Street News, the Anthropic incident has exposed the fragility of closed-source commercial models in terms of accessibility and has conferred strategic value on open-source alternatives that extends beyond purely technical considerations.
Concurrently with the release of GLM-5.2, Tang Jie, CEO of Zhipu AI, issued a statement on the X platform:
At a time when access to cutting-edge models has been arbitrarily cut off, we are more certain of one thing: science must be global. The path to AGI must not be confined by high walls.
This timing elevates open-source from a technical strategy to a narrative of technological sovereignty. The post garnered over 880,000 views and 252 replies within 24 hours.
According to Orient Securities, open-source models—characterized by open weights, autonomy and controllability, and local deployability—represent a superior option for mitigating geopolitical risks and ensuring business continuity.
Given their leading performance, predominantly open-source nature, and relatively low API call costs, Chinese models have already secured a leading position on token distribution platforms such as OpenRouter. With the delisting of two Anthropic models, domestic model API usage is expected to rise further.
However, from a medium- to long-term perspective, declining costs and lower access barriers could drive concurrent growth in token consumption and computing power demand. For investors, the rising market share of open-source models and surging demand for computing power are becoming key variables driving the revaluation of the AI industry chain.
Editor/melody