
英偉達將整合LPU技術推出全新推理芯片,OpenAI重金跟進,標誌AI算力主戰場從訓練切換至推理。申萬宏源研究指出,推理時代正催生四大新趨勢:CPU部署場景增多、LPU專用架構崛起、國產芯片加速突破、算力需求從訓練轉向海量Token消耗。隨着芯片走向訓練與推理分工、系統向三層架構演進,高性價比推理芯片廠商將成最大受益者。
$英偉達 (NVDA.US)$ 整合LPU(語言處理單元)技術、OpenAI多線押注推理芯片,正在將AI算力競爭的主戰場從訓練切換至推理。申萬宏源研究認爲,2026年算力產業的核心關鍵詞將是推理,Token消耗總量與技術範式均將圍繞這一主題深度重構。
2月28日,據《華爾街日報》報道,英偉達計劃在下月的GTC開發者大會上發佈一款整合了Groq「語言處理單元」(LPU)技術的全新推理芯片,英偉達首席執行官黃仁勳稱其爲「世界從未見過」的全新系統。OpenAI已同意成爲該處理器的最大客戶之一,並將向英偉達購買大規模「專用推理產能」。
 與此同時,OpenAI上月還與初創公司Cerebras達成數十億美元計算合作,後者稱其推理芯片速度已超越英偉達GPU(圖形處理器)。這一系列動向表明,AI巨頭正在從訓練算力的軍備競賽,轉向推理算力的多線佈局。
與此同時,OpenAI上月還與初創公司Cerebras達成數十億美元計算合作,後者稱其推理芯片速度已超越英偉達GPU(圖形處理器)。這一系列動向表明,AI巨頭正在從訓練算力的軍備競賽,轉向推理算力的多線佈局。
申萬宏源報告指出,Token經濟時代,推理算力正迎來四大趨勢:一是純CPU(中央處理器)部署場景增多,低成本推理需求加速算力下沉;二是LPU等專用架構崛起,挑戰GPU在推理環節的主導地位;三是國產算力芯片加速突破,供應鏈多元化趨勢明確;四是推理算力的需求結構從「單次訓練」向「海量Token消耗」轉變,性價比成爲核心競爭要素。
報告表示,能夠提供充足、高性價比推理芯片的廠商將最爲受益,而CPU、LPU及國產芯片的共同突破,正構成這一輪算力格局重塑的核心線索。
推理需求全面爆發,Token消耗創歷史新高
申萬宏源研究認爲,需求持續擴張的背後是兩大結構性驅動力:一是大模型貨幣化加速,Claude等模型開始嚮應用端切入,發佈多款行業插件;二是Agent落地提速,openclaw、千問Agent等產品標誌着Agent正進入真實的工作與生產場景,而每一次模型調用和Agent任務執行,背後均需大量推理算力支撐。
申萬宏源研究援引數據顯示,春節期間國內頭部大模型推理量大幅增長:豆包除夕當天推理吞吐量達633億tokens,元寶月活躍用戶達1.14億,千問「春節大免單」活動參與人數超1.2億。
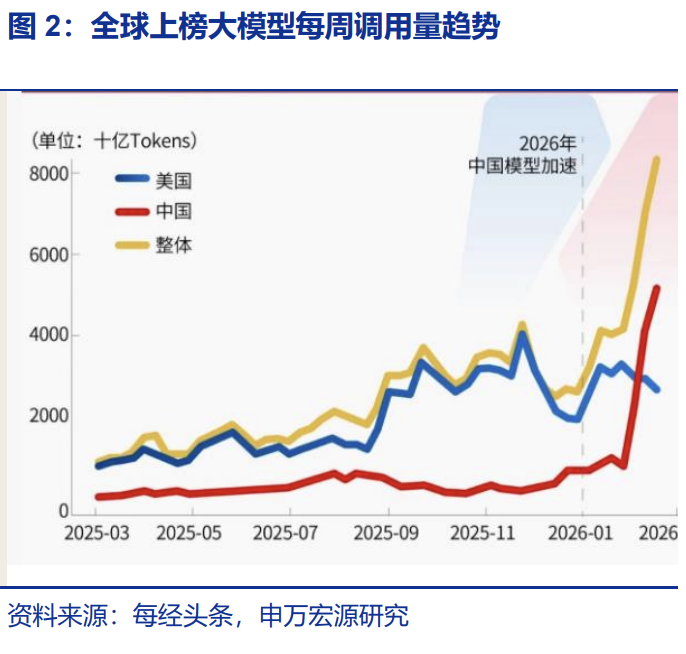
全球AI模型API聚合平台OpenRouter的數據進一步揭示了這一趨勢的量級。2月9日至15日當週,中國模型以4.12萬億Token的調用量首次超過美國模型的2.94萬億Token;16日至22日當週,中國模型調用量進一步衝高至5.16萬億Token,三週大漲127%,全球調用量前五的模型中中國佔據四席。
LPU成新貴,訓練與推理芯片走向分化
英偉達斥資200億美元獲取Groq核心技術許可,並在「核心聘用」交易中吸納了包括創始人Jonathan Ross在內的高管團隊。申萬宏源研究認爲,這一交易標誌着純推理芯片的重要性已獲得頂級玩家的正式認可。
LPU與傳統GPU的架構差異,正是其在推理場景中具備效率優勢的根本原因。AI推理分爲預填充和解碼兩個階段,大型模型的解碼過程尤其緩慢,而LPU針對延遲和內存帶寬這兩大推理瓶頸進行了專項優化。據華爾街見聞此前報道,英偉達即將發佈的新品可能涉及下一代Feynman架構,或採用更廣泛的SRAM集成方案,甚至通過3D堆疊技術將LPU深度整合其中。
申萬宏源研究據此判斷,未來AI芯片將形成明確的技術分工格局:訓練端繼續沿用GPU-HBM組合,推理端則演進爲ASIC+LPU-SRAM+SSD的組合方案。隨着算力需求從訓練向推理切換,專注推理芯片的廠商將迎來發展機遇。
推理系統全面革新,CPU與網絡需求同步提升
從單一芯片到系統層面的革新,是本輪推理算力升級的另一重要維度。申萬宏源研究指出,隨着應用場景從chatbot轉向Agent,算力系統對延遲、吞吐與思考深度的要求同時提升,推動系統架構向三層網絡演進。
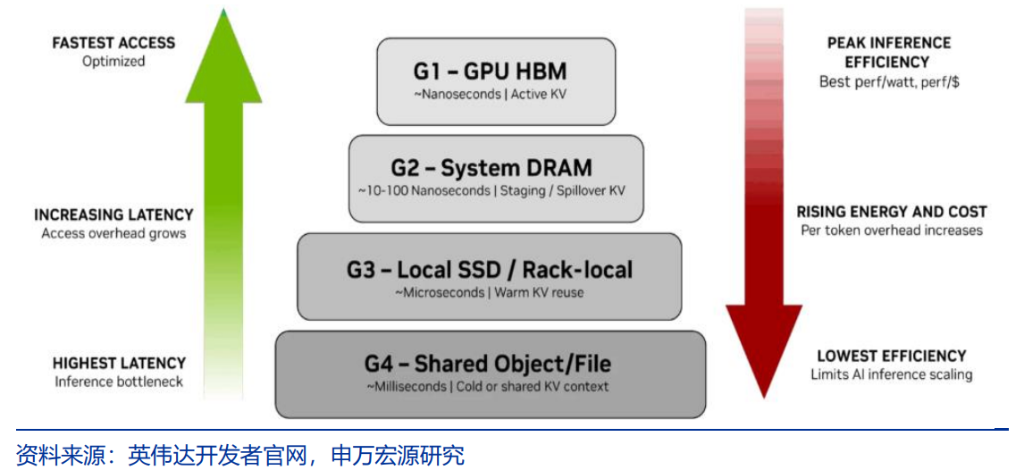
第一層爲快反應層,由搭載SRAM的純推理芯片提供極致低延遲反饋;第二層爲慢思考層,使用超大吞吐算力集群負責複雜邏輯推演,多核多線程CPU在此層的需求將顯著增加;第三層爲記憶層,對應英偉達發佈的ContextMemory System,通過Bluefield4 DPU管理的SSD存儲Agent的長期記憶與KV Cache。
英偉達在硬件層面也在調整策略。此前將Vera CPU與Rubin GPU捆綁部署的標準做法,在特定AI智能體工作負載下被證明成本過高。英偉達本月宣佈擴大與Meta Platforms的合作,完成首次大規模純CPU部署,以支持Meta的廣告定向AI智能體,標誌着公司正超越單一GPU銷售模式。
國產算力加速突破
申萬宏源研究認爲,國產推理芯片的技術升級值得重點關注,且存在市場預期差。
在技術層面,新一代國產推理芯片實現了多項根本性提升:新增支持FP8/MXFP8/MXFP4等低精度數據格式,算力分別達到1P和2P;大幅提升向量算力,採用支持SIMD/SIMT雙編程模型的新同構設計;互聯帶寬相比前代提升2.5倍,達到2TB/s。
尤爲值得關注的是,芯片層面實現了PD分離:通過自研兩種不同規格的HBM,分別構成面向Prefill和推薦場景的PR版本,以及面向Decode和訓練場景的DT版本。其中PR版本採用低成本HBM,可大幅降低推理Prefill階段的投資成本,預計於2026年Q1推出。
供應鏈層面,國產封測廠商的進展提供了佐證。根據某頭部封測企業首輪問詢答覆函,其2.5D封裝業務收入主要來自高性能計算芯片封裝服務,該項收入從2022年的0.5億元快速增長至2024年的18.2億元,側面印證國產算力芯片供給能力持續提升,供應鏈國產化進程加快。
編輯/lambor