
SemiAnalysis首度拆解英偉達Blackwell架構:在AI負載下,張量核心與內存帶寬整體逼近理論峰值,但性能高度依賴指令形狀與軟件調優。2SM MMA實現近乎完美擴展,但SMEM帶寬與跨Die約300週期延遲成爲關鍵瓶頸。研究揭示,Blackwell性能釋放不取決於硬件上限,而取決於調度與優化能力。
$英偉達 (NVDA.US)$ Blackwell GPU代表了近年來最重大的GPU微架構變革之一,但迄今缺乏詳盡的官方白皮書。
知名半導體研究機構SemiAnalysis歷時數月,對Blackwell架構進行了系統性微基準測試,首次公開了該架構在AI工作負載下的硬件性能上限數據。
 測試結果顯示,Blackwell在張量核心(Tensor Core)吞吐量、內存子系統帶寬及新型2SM MMA指令等關鍵維度上均接近理論峰值,但性能表現高度依賴指令形狀配置,部分場景下存在明顯的帶寬瓶頸。這一發現對AI基礎設施投資者和芯片採購方具有直接參考價值——架構潛力能否充分釋放,取決於軟件層面的精細調優。
測試結果顯示,Blackwell在張量核心(Tensor Core)吞吐量、內存子系統帶寬及新型2SM MMA指令等關鍵維度上均接近理論峰值,但性能表現高度依賴指令形狀配置,部分場景下存在明顯的帶寬瓶頸。這一發現對AI基礎設施投資者和芯片採購方具有直接參考價值——架構潛力能否充分釋放,取決於軟件層面的精細調優。
SemiAnalysis已將相關基準測試代碼庫開源,測試所用B200節點由NEBIUS和Verda提供。研究團隊同時宣佈,後續將擴展至TPU Pallas內核、Trainium NKI內核及AMD CDNA4彙編的基準測試。
架構核心變化:TMEM引入與2SM MMA
從Hopper到Blackwell,英偉達對MMA相關指令的PTX抽象層進行了多項重要調整。
最顯著的變化是引入了張量內存(TMEM)用於存儲MMA累加器。在此前架構中,線程隱式持有MMA運算結果;Blackwell改爲由軟件在MMA作用域內顯式管理TMEM,改變了線程與計算結果之間的所有權關係。
與此同時,tcgen05操作現在由單一線程代表整個CTA(協作線程陣列)發出,而非此前Hopper架構中以warp或warpgroup爲單位發出。這一變化在CuTe MMA原子中有直接體現:Blackwell使用ThrID = Layout<_1>,而Hopper使用ThrID = Layout<_128>。
Blackwell還引入了TPC作用域的TMA和MMA,支持兩個協同CTA跨SM對執行tcgen05.mma,共享操作數,從而在降低每個CTA共享內存帶寬需求的同時,提供更高運算強度的MMA指令。此外,該架構原生支持帶微縮放的亞字節數據類型,並引入了集群啓動控制(CLC)作爲持久化CTA內核中動態工作調度的硬件支持。
芯片物理佈局:雙Die架構與300週期跨Die延遲
SemiAnalysis通過逆向工程手段,揭示了B200芯片的物理拓撲結構。
研究團隊利用PTX %%smid指令,通過啓動不同大小的集群來反向推斷SM到GPC(圖形處理集群)的映射關係。結果顯示,B200存在部分TPC獨佔邏輯GPC的情況,這些TPC從不與其他TPC協同調度。
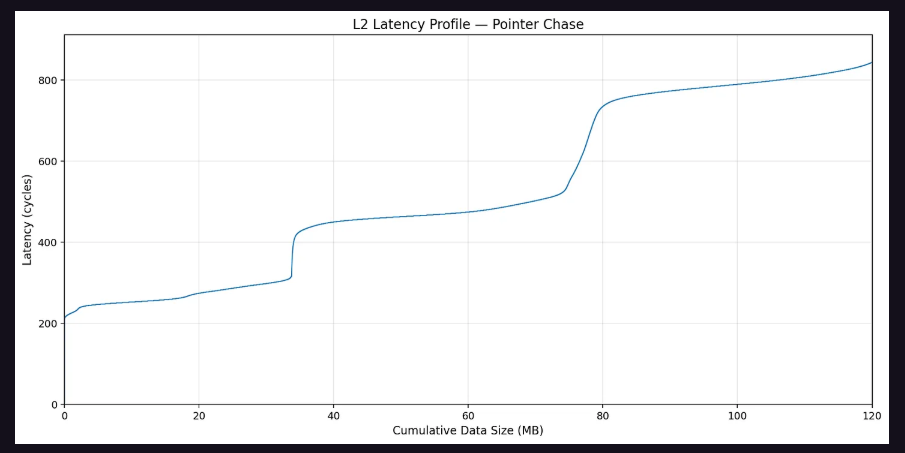
通過讓每個SM遍歷填滿L2緩存的指針追蹤數組並測量各SM間的訪問延遲,研究團隊構建了SM間距離矩陣。矩陣清晰呈現出兩組SM,平均L2訪問延遲差距超過300個時鐘週期,對應的正是兩個Die之間的跨Die訪問懲罰。
基於此,研究團隊推斷B200的Die級TPC分佈如下:
Die A:各GPC分別包含10、10、10、9個TPC
Die B:各GPC分別包含9、9、9、5+3個TPC
這一物理佈局差異意味着,即便邏輯配置相同的兩塊GPU,其物理SM分佈也可能不同,構成潛在的性能非確定性來源。
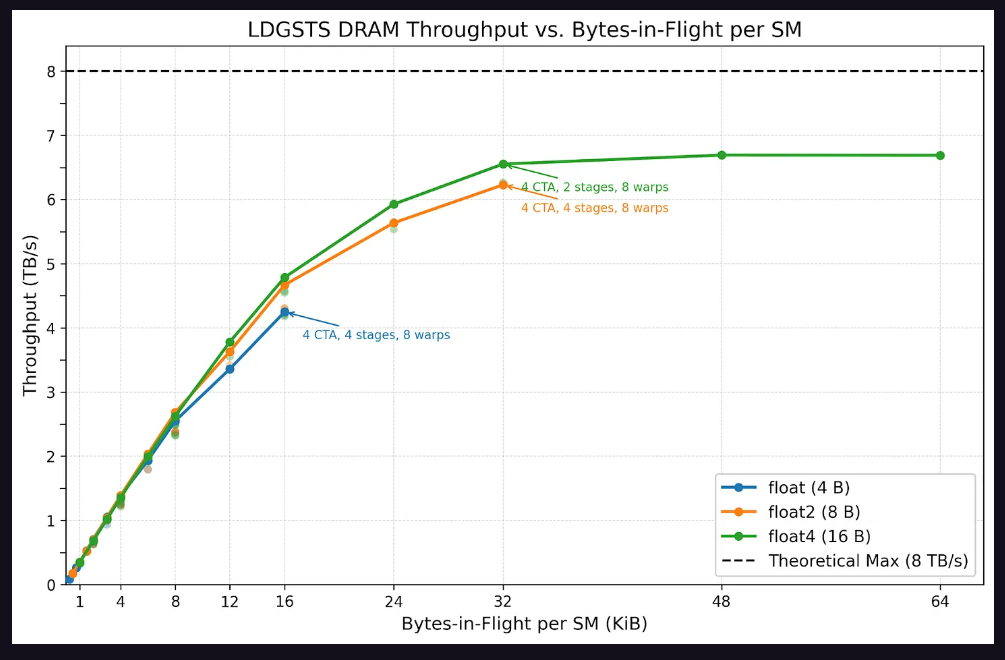
內存子系統:LDGSTS與TMA的性能邊界
內存子系統測試聚焦於兩類異步拷貝指令:LDGSTS(異步拷貝)和TMA(張量內存加速器)。
LDGSTS方面,測試覆蓋了FlashInfer多頭注意力(MHA)內核的典型配置。結果顯示,LDGSTS內存吞吐量在32 KiB在途字節時飽和,峰值約爲6.6 TB/s。16字節加載在相同在途字節數下略優於8字節加載,且消耗更少執行資源。延遲測試顯示,LDGSTS基線延遲約爲600納秒,在途字節超過8 KiB後延遲接近翻倍,原因在於大量線程因MIO(內存輸入輸出)節流而停滯。
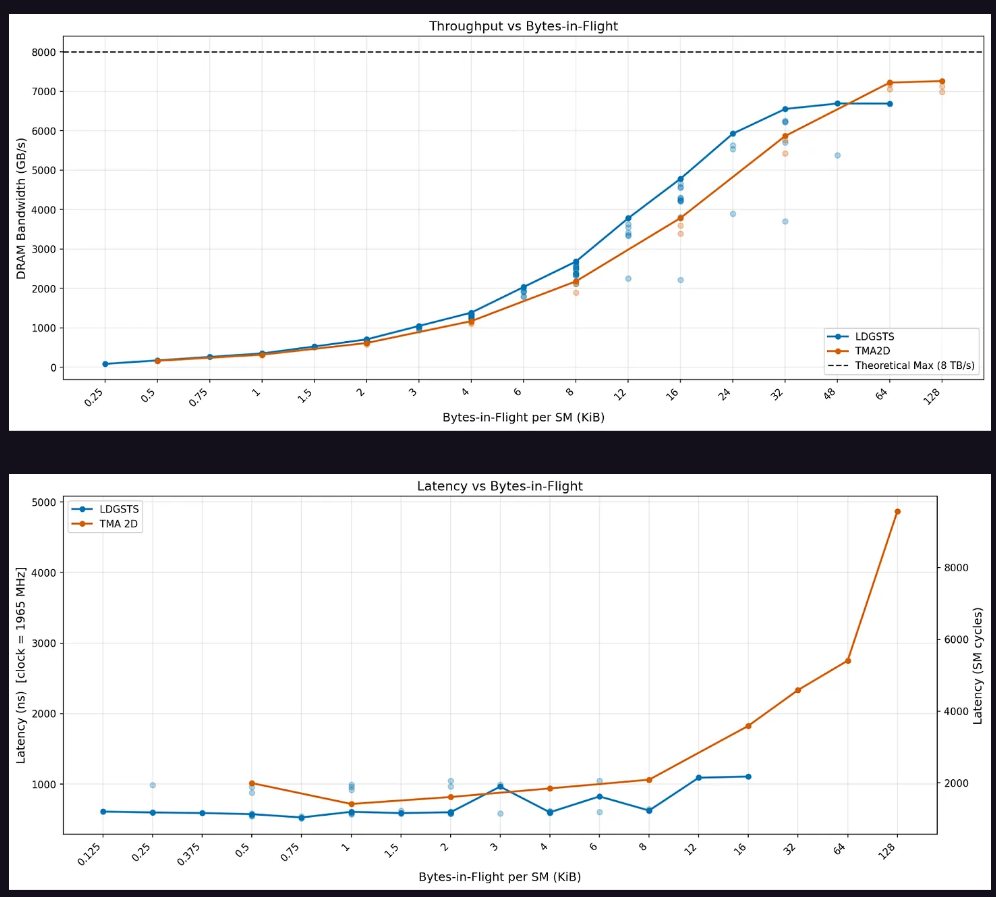
TMA方面,峰值吞吐量的達到明顯晚於LDGSTS。在低於32字節在途數據時,異步拷貝吞吐量略優於TMA;超過該閾值後TMA追上並可持續擴展至128 KiB。延遲方面,在途數據低於12 KiB時異步拷貝延遲略低,超過後TMA延遲大幅攀升。
TMA多播測試顯示,顯式TMA多播可完美消除L2流量,實現理想的"1/集群大小"L2字節比。隱式多播(各CTA獨立發出TMA加載至相同數據)在有效內存吞吐量上與顯式多播相當,但在超過64字節在途數據後,L2緩存流量削減效果開始下降。
張量核心性能:形狀依賴性顯著,2SM MMA實現完美弱擴展
張量核心測試是本次研究的核心部分,結果揭示了Blackwell MMA性能對指令形狀的高度敏感性。
吞吐量方面,對於1SM MMA,M=64的配置最高僅能達到理論峰值的50%,而M=128可接近100%。這證實M=64僅利用了一半數據通路。對於2SM MMA,M=128在N=64時吞吐量爲峰值的90%,其餘N尺寸均接近100%;M=256則在所有配置下均維持接近100%的峰值吞吐量,因爲M=256等效於每SM處理M=128,可充分利用完整數據通路。
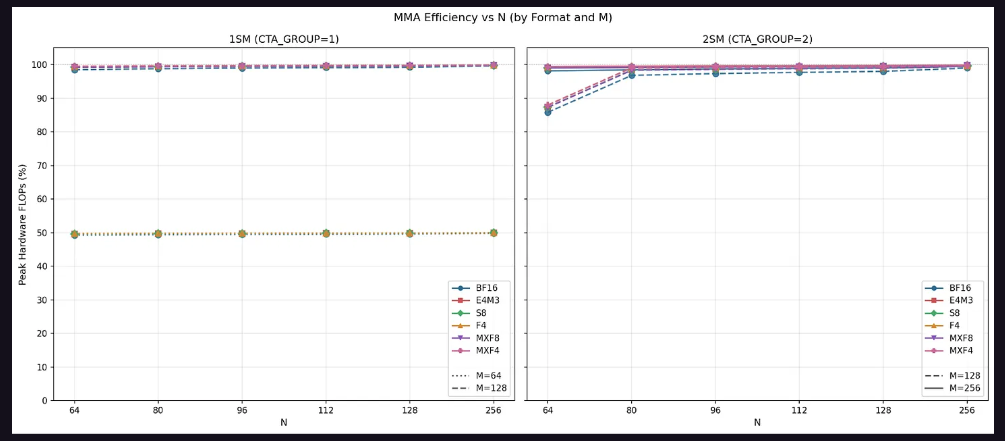
AB佈局影響同樣顯著。當兩個輸入矩陣均存儲於共享內存(SS模式)時,M=128在N<128時存在明顯的SMEM帶寬瓶頸。以FP16爲例,硬件每週期可執行8192 MMA FLOP,SMEM帶寬爲128 B/週期,計算表明M=128 N=64 K=16配置下SMEM需要48個週期,而數學運算僅需32個週期,即指令受SMEM帶寬限制。所有數據類型均存在這一規律——雙操作數均在SMEM中的MMA指令,在N<128時均受SMEM帶寬約束。
2SM MMA實現了完美的弱擴展,相對於1SM MMA在使用兩倍計算資源時獲得2倍加速。在SS模式的小形狀配置下,由於操作數B在兩個SM間分片,甚至出現超過2倍的加速。研究結論明確:應始終使用給定SMEM tile尺寸下可用的最大指令形狀,以獲得最高吞吐量。
延遲方面,所有配置下延遲均隨N從64增至128線性增長,N=256時出現跳躍。數據類型延遲排序呈現規律性:S8 < BF16 = E4M3 = F4 < MXF8 = MXF4,研究團隊認爲整數運算功耗效率更高導致S8最快,而微縮放數據類型的縮放因子計算引入了輕微額外開銷。
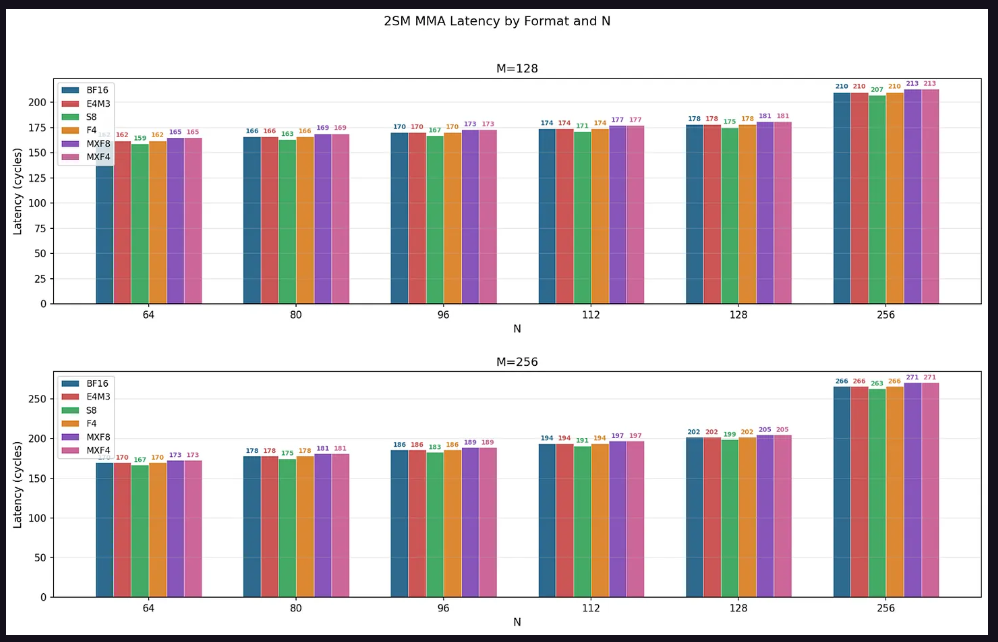
實際在途指令數測試顯示,在典型內核使用的1至4條在途MMA指令場景下,4條在途MMA的吞吐量上限約爲理論峰值的78%至80%,且1SM MMA比2SM MMA高出約5個百分點。
編輯/KOKO